






Table of Contents
- 1 Automated Content Creation: When to Use It and How to Keep Quality High
- 1.1 When to Use Automated Content Creation
- 1.2 Types of Automation and Where They Fit in the Content Lifecycle
- 1.3 End-to-End Automated Content Workflow Using Ranklytics
- 1.4 Quality Control Checklist for Automated Content
- 1.5 Measuring Quality and Running Experiments
- 1.6 Governance, Legal, and Ethical Considerations
- 1.7 Toolset and Integrations
- 1.8 Frequently Asked Questions
Automated Content Creation: When to Use It and How to Keep Quality High
Automated content creation can multiply output quickly, but left unchecked it amplifies factual errors, voice drift, and ranking risk. This guide gives clear decision criteria for when to automate, a practical Ranklytics-centered workflow that blends AI drafts with human review, and a concise quality checklist covering E-E-A-T, factual verification, and SEO controls. Expect plug-and-play templates, sample prompts, and experiment designs you can use to scale content without sacrificing search performance.
When to Use Automated Content Creation
Direct rule: use automated content creation where repeatability, low factual risk, and scale matter more than original research. Automation wins when the content follows stable templates, draws from structured data, or serves update-heavy needs.
Decision criteria you can score
How to score: rate each prospective asset on four dimensions from 1-5 and prefer automation when the total is high. Keep the scoring fast – a 60-second triage per asset is enough for a queue of hundreds.
- Intent (commercial vs research): higher scores favor commercial/transactional intent where templates match user need.
- Complexity (need for original expertise): low scores favor automation; anything requiring primary research or nuanced analysis scores high and should be human-first.
- Risk (legal, medical, financial): high-risk topics should not be published without SME sign-off regardless of automation score.
- Scale (volume or update frequency): high scale or frequent refresh needs make automation worth the governance overhead.
Practical trade-off: automation reduces per-asset cost and turnaround but raises ongoing maintenance and audit work.** You gain velocity, then pay in governance: prompts, citation checks, version logs, and periodic audits become operational necessities.
Concrete example: a mid-market ecommerce team used automated content creation to produce 5,000 product descriptions from a specification feed.** They saved weeks of writer time and cut cost per SKU, but discovered a 12-week maintenance cycle where price and spec drift forced bulk refreshes and manual spot-checks.
Where automation gives the best ROI: product descriptions, localized landing pages, FAQ/knowledge-base updates, meta tags, and programmatic reports.** These are low-friction assets where AI text generation tools and content creation software map neatly to fields in a CMS or data feed.
Where to avoid publishing AI-first: investigative long-form, primary research, legal and medical guidance, and any content tied to compliance.** In practice these require subject matter expert authorship and a formal review loop before publication.
Key judgment: automation should be a force-multiplier for output and updates, not a replacement for domain authority.** If your goal is ranking for trust-sensitive queries, plan human intervention at the point of publication.

Types of Automation and Where They Fit in the Content Lifecycle
Direct point: automated content creation is a set of distinct capabilities, not a single switch — each belongs to a specific slot in the pipeline and carries different risks, costs, and governance needs.
Research and ideation: signal collection, not decisions
Where it fits: use data-driven tools to surface topic clusters, SERP intent signals, and competitive gaps.** These outputs are high-value automation because they reduce analyst hours without touching published copy.
Trade-off: automated discovery will surface obvious, high-volume opportunities but miss nuanced angles that require human market context. Treat algorithmic topic picks as hypotheses, not final briefs — require a one-minute human triage before generation.
Structure, templates, and outline automation
Where it fits: generating H2/H3 outlines, canonical examples, and templated sections works best when the content follows a predictable pattern.** This reduces cognitive load for writers and keeps internal linking and schema consistent across hundreds of pages.
Limitation: automatic outlines can echo the highest-ranking pages too closely. Add a required brief field that lists competitor excerpts and a unique angle to force differentiation before draft generation.
Draft generation and the human-in-the-loop boundary
Where it fits: LLMs are fastest as first-draft engines for low-risk, template-friendly content and for converting structured data into readable text.** Use GPT-4 or similar models with conservative settings (temperature low, max tokens capped) and explicit instructions to cite sources.
Practical consideration: guard against unverified claims by embedding a mandatory claims table in the draft output that flags statements needing a source or SME confirmation. If the claims table lists more than three unverified assertions, route the draft to subject matter review automatically.
Where automation excels downstream: metadata generation, schema markup, internal link suggestions, and meta descriptions are safe automation targets.** These tasks are deterministic and can be validated with automated QA scripts before publish, reducing manual churn.
Risk to watch: bulk updates or programmatic refreshes can trigger ranking volatility if they change the page's core information or intent. Stagger rollouts and test a subset before sitewide pushes.
- Minimum guardrails: require a source list attached to every generated draft
- Deterministic template tokens: lock brand phrasing and CTA fields so automation cannot rewrite them
- Provenance metadata: store prompt, model, and generation timestamp in the CMS for audits
- Fail-safe thresholds: automatic drafts that exceed a configured risk score must be human-approved
Concrete Example: A B2B SaaS marketing team used automated blog outlines and draft generation to expand topic clusters into localized pages. Ranklytics produced the briefs and GPT-4 drafted first versions; legal and product SMEs reviewed only pages flagged by the claims table. The team limited automation to mid-funnel content — this reduced time-to-publish by 60% while keeping high-risk pages entirely human-authored.
Judgment that matters: automation gives the best leverage when applied to exactly those parts of the lifecycle that are repeatable and verifiable. If your workflow treats automation as a shortcut for expertise, expect degraded performance and higher editorial debt. Instead, design automation to hand off work at well-defined control points.
outline -> human review, draft -> claims table, meta -> auto-validate) and enforce those mappings in your CMS. See how Ranklytics integrates briefs and tracking at Ranklytics features.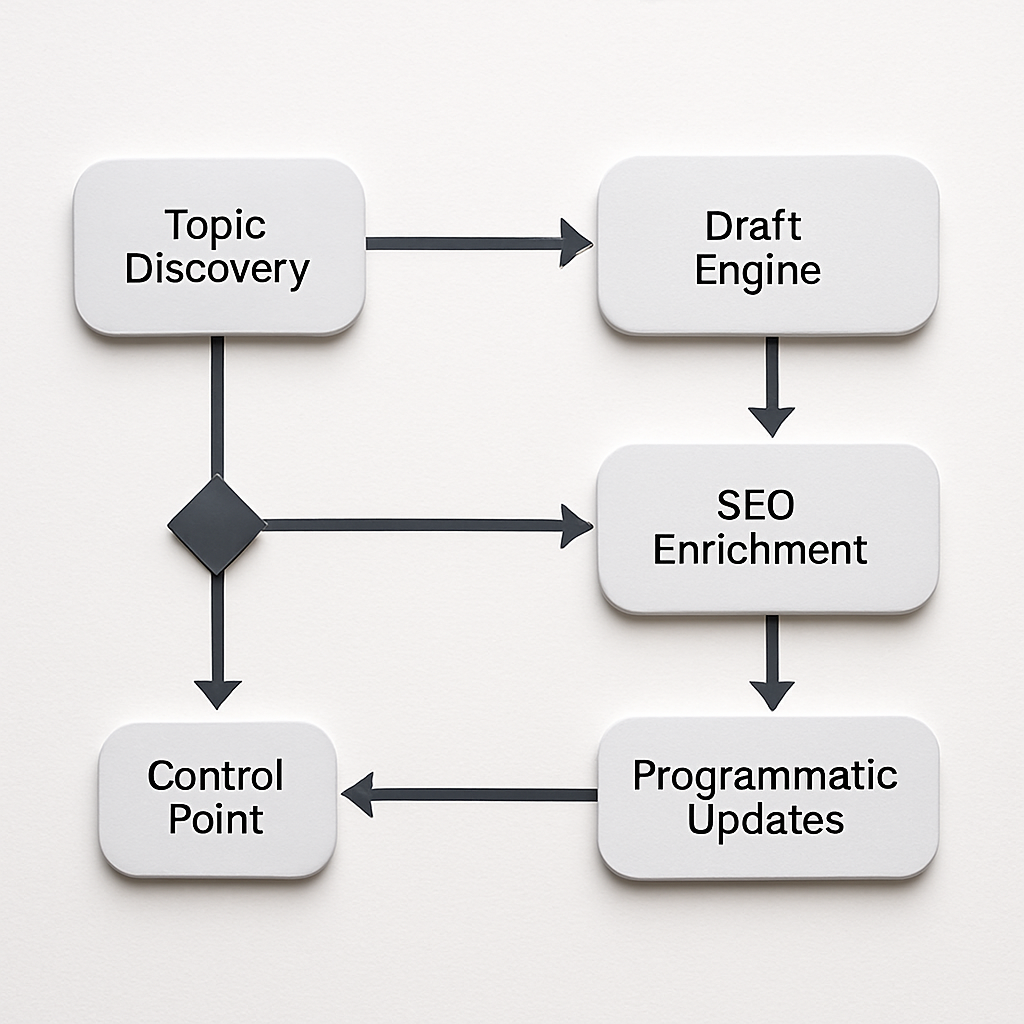
End-to-End Automated Content Workflow Using Ranklytics
Straight to the point: a reliable automated content creation pipeline is a sequence of handoffs and validations, not an LLM running unchecked. Below is a practical, enforceable workflow that uses Ranklytics for planning and tracking, an LLM for controlled drafting, and human review gates where they matter most.
Operational steps
- Step 1 — Prioritize with Ranklytics: ingest keywords, surface topic clusters, and assign priority scores. Export the brief payload (intent, target phrases, competitor snippets) to your draft queue so generation is data-backed.
- Step 2 — Produce a focused brief: include mandatory fields: target intent, required sources, forbidden claims, brand tokens, and a short unique angle. Store the brief in the CMS as canonical metadata for the page.
- Step 3 — Controlled draft generation: call your LLM with conservative parameters and the brief. Require the draft to include a claims table and inline source markers. Save prompt, model, and generation hash for auditability.
- Step 4 — Triage and SME review: run an automated claims scan; if the draft has more than N unreferenced claims or a risk tag, route to a subject matter expert. Use a one-screen reviewer task that shows claims, suggested sources, and quick-accept buttons.
- Step 5 — SEO enrichment and QA: apply on-page guidance (use SurferSEO or Clearscope if used), attach schema markup, validate mobile rendering, and run plagiarism and readability checks before scheduling publish.
- Step 6 — Staged publish and monitor: rollout in cohorts (5–10% of pages), monitor CTR, impressions, and position in Ranklytics plus Google Search Console. Pause or rollback if negative signals appear.
Practical trade-off: this pipeline buys scale but creates operational artifacts: prompt drift, audit logs, and recurring verification work. Expect to invest in lightweight orchestration (Zapier, native Ranklytics integrations) and a small QA team to keep long-term warranty on content quality.
Concrete example: A regional services company used Ranklytics to generate localized landing pages for 1,200 locations. Ranklytics produced briefs per market, an LLM drafted pages, and a small ops team reviewed only pages flagged by the claims table. The process allowed the team to publish at scale while limiting legal and factual review to ~8% of pages.
Automate deterministic pieces (meta, schema, templated sections) and force human review on any novel claim — that split is where automation reliably reduces cost without increasing ranking risk.

Quality Control Checklist for Automated Content
Practical assertion: A usable quality checklist is not a laundry list — it is a compact, enforceable set of gates that converts model outputs into publishable assets. Make checks measurable, automated where possible, and risk-tiered so you do not bog down throughput.
Core checkpoints (apply per-asset, risk-weighted)
- Provenance tag: every generated claim must include at least one source URL in the metadata. The CMS should reject publication if linked sources return a 4xx/5xx error or are paywalled.
- Claim risk score: compute a simple numeric score for each assertion using rules: topic sensitivity (legal/health/finance), novelty of claim, and source authority. Route any draft with a claim score above your threshold to an SME.
- Canonical-data fidelity: cross-check all product names, specs, prices, and identifiers against your canonical dataset. Mismatched numbers are a hard stop for publication.
- Brand-voice lock: enforce locked tokens for CTAs, product names, and mandated legal phrases so automation cannot rewrite critical brand elements.
- SEO sanity-pass: validate title, H1, H2 structure, meta description length, and that primary target phrases from the Ranklytics brief appear in expected nodes.
- Plagiarism and overlap check: run a similarity scan and flag items above your threshold; use human judgment for common industry phrases and boilerplate.
- Accessibility and schema: verify alt text present for images, correct ARIA roles where applicable, and that required schema nodes are generated for the content type.
- Publish gating and rollback criteria: stage publish to a small cohort, set automatic alerts for CTR or ranking drops, and have a documented rollback path.
- Audit log: store prompt text, model name/version, generation timestamp, editor ID, and final approval decision in an immutable audit field.
Trade-off to accept: running every check at 100% coverage negates the speed benefit of automated content. Practical teams tier assets: low-risk product descriptions use automated validators only; anything that touches compliance or revenue gets full SME review. Expect to tune thresholds during the first two sprints.
Concrete example: A SaaS support team automated 400 FAQ updates. They required provenance tags and canonical-data checks for all items, but only routed FAQs with a high claim risk score to engineers. That left roughly 60 items for human review while 340 passed automated gates and published after schema and SEO sanity checks.
Judgment that matters: tooling is good at catching deterministic errors and surface overlap, but it misses subtle mistranslations of policy or nuance in expert claims. Rely on automation to scale verification work, not to replace domain judgment — build your escalation rules to reflect that boundary.
Start small: pick three gates you will not waive (provenance, canonical-data fidelity, and audit log). Automate those first, then expand checks after two release cycles.

Measuring Quality and Running Experiments
Surface metrics mislead. Organic clicks and impressions are necessary, not sufficient, signals for automated content creation — you need experiments that link content changes to durable ranking and business outcomes while controlling for noise.
What to measure and why it matters
Primary search metrics: track average position, organic clicks, and CTR at the query level so you can see whether the content is winning for its intended intent or cannibalizing adjacent queries. Use Google Search Console and surface-group these signals in Ranklytics features for rolling comparisons.
Engagement and conversion metrics: measure time on page, scroll depth, and explicit conversions (signup, demo request) to detect degraded user experience even if raw traffic looks steady. These are the fastest indicators that an AI draft missed the user's need.
Content health signals: track provenance completeness (source links present), claim correction rate, and similarity scores from plagiarism tools as operational metrics. High correction rates mean the workflow is producing editorial debt, even if SEO numbers are okay.
- Define success before you publish: the metric that matters must map to the page intent (e.g., leads for product pages, time on page for tutorials).
- Segment by query and cohort: run analysis at the query level and by page cohorts (topic, template, risk-tier) to avoid averaging away failures.
- Set actionable thresholds: decide what triggers rollback or SME review, for example a sustained position drop versus a one-day variance.
Experiment designs that give reliable answers
A/B on live pages is feasible and practical. Use headline swaps, first-paragraph replacements, or localized content toggles so search signals change incrementally and you can attribute effects. Full-page swaps are higher risk and should be staged only after smaller tests pass.
Phased rollouts reduce surprise: publish to a small, random cohort first, monitor search and engagement for an observation window, then increase exposure. This avoids widespread ranking volatility and gives time to catch indexing quirks.
Trade-off to accept: faster rollouts mean quicker wins but higher false positives because SERP behavior is noisy. Slower tests give confidence but cost time. Choose speed when performance risk is low and choose rigor when queries are trust-sensitive.
Concrete Example: A SaaS content team replaced the intro sections on a set of help articles for routine troubleshooting topics with AI-generated drafts, limited to a small cohort. They monitored query-level clicks, support-ticket volume for the same issues, and changes in best-answer rankings for several weeks. The experiment showed higher clicks but no reduction in support tickets, so the team iterated on the draft prompts and re-ran the test before scaling.
Important: short-term traffic spikes often reflect novelty or SERP feature placement. Only scale automation after engagement and conversion signals align with search performance for a sustained window.
Final judgement: treat experiments as learning engines, not one-off validations. If an automated workflow repeatedly fails the same gates, fix the brief, not the model. If tests pass but editorial debt accumulates, invest the savings into stronger governance rather than broader rollouts.
Governance, Legal, and Ethical Considerations
Hard line first: automated content creation shifts legal and reputational risk from individual writers to the platform and process. Treat model outputs as draft artifacts that can create liability if published without governance—this is operational, not theoretical.
Core governance controls you must implement
- Immutable audit trail: log prompt text, model name/version, generation timestamp, source URLs, editor IDs, and final sign-off. Store logs where regulators and auditors can retrieve them.
- Vendor risk and contract clauses: require model vendors to disclose data-retention policies, the right to audit, and explicit warranties against training on proprietary customer data.
- Prompt and data hygiene: ban embedding customer PII or proprietary datasets in prompts; automate redaction and enforce retention limits for prompt logs.
- IP and copyright controls: require licenses for third-party datasets used in training or grounding; run similarity and provenance checks before publish.
- Disclosure policy tuned to context: a short consumer-facing disclosure for editorial content, and internal labels for compliance or legal review; balance transparency with credibility.
Trade-off to accept: full transparency on AI use can build trust but also invite scrutiny and legal discovery. For B2B or regulated content, prefer robust internal labeling and retained evidence over public banners; for consumer editorial pieces, a clear, short disclosure aligned with Google helpful content guidance is safer.
Practical limitation: relying on vendor promises is insufficient. Real-world compliance requires contractual audit rights and a repeatable process to verify training-data provenance or to demonstrate that a generation did not reproduce copyrighted material.
Concrete example: A fintech firm automated routine explainers and account FAQs using content creation AI tools. Legal required that any article touching deposit rates or regulatory requirements be routed through a two-step review: compliance review within 48 hours and a signed record stored with the draft. The team also implemented automated redaction of account identifiers in any prompts and a retention policy that purges prompt logs after 18 months.
Judgment that matters: governance is the multiplier that determines whether automation is a liability or an asset. Teams that skimp on auditability and contractual protections will incur higher legal and remediation costs than the savings from faster drafting.
Enforce these three non-negotiables: an immutable audit trail, contractual vendor assurances with audit rights, and automated PII redaction for all prompts.
Toolset and Integrations
Tool selection and integration design determine whether automated content creation scales or becomes an operational liability. Pick for predictable data flows, auditability, and failure modes, not shiny feature lists.
Design principle: data contracts first
Define a minimal data contract that travels with every asset: brief id, target intent, source list, model version, prompt hash, claims table, reviewer id, and publish status. Integrations that preserve and surface those fields in the CMS and analytics stack save you hours of debugging and make rollbacks possible.
| Tool category | Representative examples | Integration note |
|---|---|---|
| Planning and briefs | Ranklytics | Expose brief payloads via webhook or API so briefs become canonical metadata in the CMS |
| Text generation | OpenAI GPT-4 / in-house LLM | Store prompt, model, and generation hash; prefer low-temperature templates for repeatable outputs |
| SEO and content tuning | SurferSEO, Clearscope | Push content to SEO tools for scoring, then persist the optimization suggestions back to the CMS |
| Quality and plagiarism | Grammarly Business, Copyscape | Run programmatic checks pre-publish and record similarity scores in the audit fields |
| Orchestration and automation | Zapier, n8n, native APIs | Use event-driven flows for real-time handoffs; fall back to batch exports only for low-frequency jobs |
| Analytics and monitoring | Google Search Console, GA4 | Ingest query- and page-level signals into Ranklytics to close the feedback loop |
- Operational checks: design for API rate limits, retry logic, idempotent generation calls, and clear error handling so a failed draft does not publish incomplete content
- Privacy and prompt hygiene: ensure prompt redaction and storage policies align with your contracts and with OpenAI usage policies
- Provenance surfacing: surface source URLs and claims table prominently in the editor UI so reviewers do not have to hunt for context
Trade-off to accept: fine-tuning models gives consistent voice but requires continuous retraining, dataset governance, and higher cost. For most mid-market programs, structured prompts plus embedded metadata outperform custom fine-tuning on ROI and maintainability.
Concrete example: a regional marketing team pushed Ranklytics briefs via webhook into a serverless function that called an LLM. Drafts returned with inline source markers and a claims table, and the function wrote the artifact to the CMS with provenance metadata. The team used a webhook to trigger plagiarism and SEO scoring, and only assets that passed automated gates reached the staged publish cohort.
Integration debt is the silent cost of scale – plan for versioning, prompt audits, and a simple rollback mechanism before you publish at volume
Next consideration: pick the smallest integration that achieves auditability and closed-loop monitoring. For most teams that is Ranklytics to LLM to CMS with automated QA gates and GSC feedback, not a fully custom model stack.
Frequently Asked Questions

Written by
James ChenJames is a content marketing expert and former agency lead who has managed SEO programs for Fortune 500 brands. He focuses on keyword strategy, content gap analysis, and building scalable content operations. He writes about the intersection of AI and modern marketing.